Configuring the Import Map Header
ImportIDs are used by the import process to determine if a record already exists in ClientSpace to update the record if it exists or create a new one if no match is found. Because of this, it is vital to have a unique ImportID for each row of the import file that is distinct across the entire dataset. ImportIDs should never be re-used unless the intention is to update an existing record.
To begin creating a custom import:
- Go to System Admin
 > Advanced > Configure Import.
> Advanced > Configure Import.
The Import Map Header Search dashboard opens. - Click Add.
The Import Map Header Detail form opens.
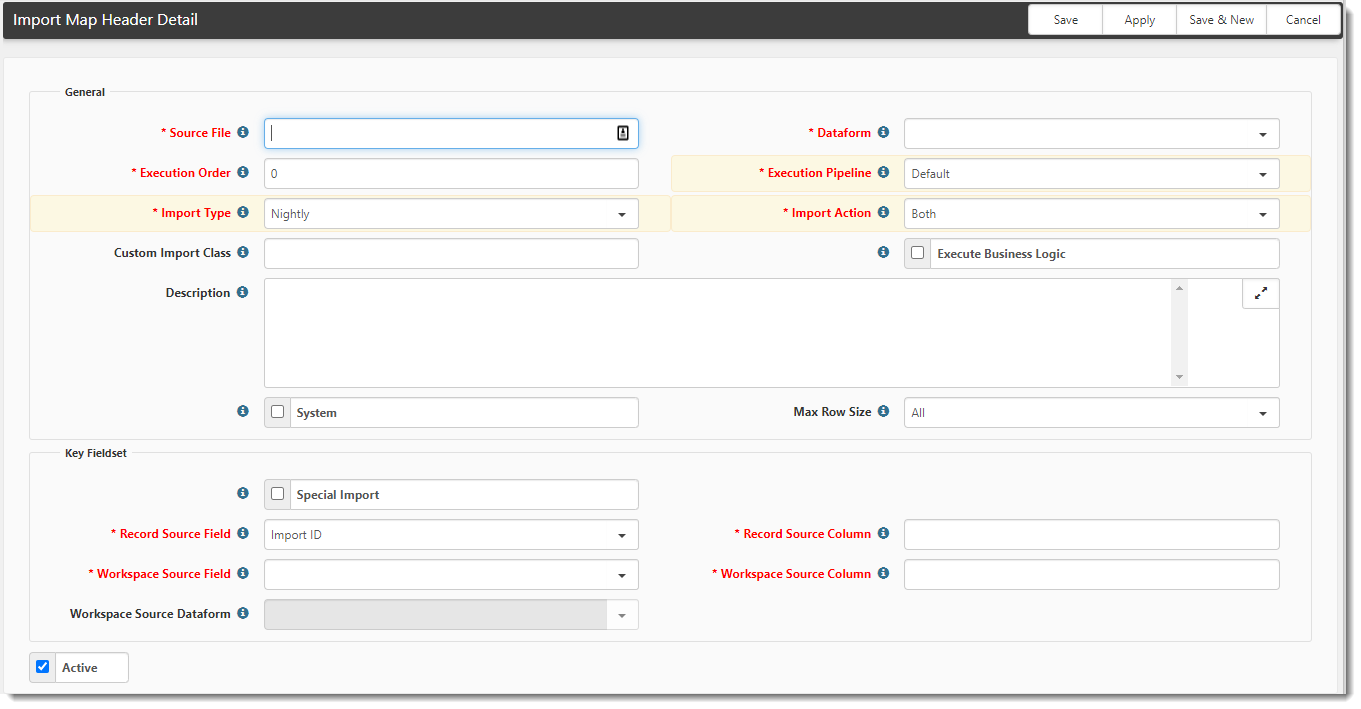
- Begin creating a new import configuration by completing the fields.
|
Source File |
This is the name of the file that you are importing. The file name should include the file extension (commonly CSV). A best practice is to add an asterisk before the file extension to account for variations in the file name. |
| Dataform | Select the dataform to receive the information. For example, if you select the Employee dataform, the data is mapped to fields in the Employee form. The system can import to dataforms associated with the primary dataform in tabs. |
|
Execution Order |
If the import runs automatically, in which order should the files import? It is important to set this appropriately if you have multiple dependent imports, such as an Employee Import, which depends on the Client Import executing first. |
|
Execution Pipeline |
When the imported records are saved, which pipeline will execute? This determines which rules are applied when the data is saved. Selecting Import, for example, runs the business rules, triggers email templates, and triggers workflows with the import pipeline selected. Note: If you are using the Pipeline Linking table to manage Pipeline Behaviors and you are configuring a new import record, the pipeline assigned a behavior of Default will auto-fill the Execution Pipeline field. If you are editing an existing import record, the Execution Pipeline entry remains intact until edited. If you change the entry, it is validated against the Pipeline Linking table. For instance, if a pipeline has been assigned a behavior of Allow or Default and you remove it, you will still be able to select it from the Execution Pipeline list. If the same pipeline is assigned a behavior of Disallow, you will not be able to add it again. |
|
Import Type |
Options include:
|
|
Import Action |
Options include:
|
|
Custom Import Class |
This field is only used if there is a specialized import code written by ClientSpace. Log an Extranet case if you have questions. |
|
Execute Business Logic |
When selected (enabled), any Workflows, Email Templates, Hard Errors, or Business Rules configured in the Execution Pipeline fire on save of the data into ClientSpace. Soft errors on the pipeline are ignored. Hard errors create Log Entries, and the associated record is not imported. |
|
Description |
Provide a brief description of the import. It is useful to use this area to distinguish the purpose of the import and where the data to be imported originates. |
|
System |
When selected (enabled), only a developer user can configure the Import Map Header and Fields. From the Import Map Header Search dashboard, when this option is enabled, Add and Delete are not available for global administrators. |
|
Max Row Size |
This field is used to identify how many rows in the file will be processed before splitting a large file into smaller pieces. This can eliminate "timeout" issues with large uploaded files. |
|
Special Import |
Only used for PrismHR technology custom import code. |
|
Record Source Field |
This is the field on the selected Dataform (in the General fieldset) for locating the record. Select ImportID or ID (Record Primary Key). |
|
Record Source Column |
Specify the name of the column in the import file that contains the value of the Record Type Field. The column name is used to match the ClientSpace record you want to update. This is always compared to the ImportID on the record to be updated. Cannot be identical to the Workspace Identifier. |
|
Workspace Source Field |
Specify the type of information on the Workspace Source Dataform to locate the workspace. The administrator can configure an import to select the appropriate workspace when inserting a row of data based on the following:
|
|
Workspace Source Column |
This is the column name on the import file that matches the Workspace record in ClientSpace. Information in this field/column is compared to the Workspace Source Field of the Workspace Source Dataform. Cannot be identical to the Records to Update. |
|
Workspace Source Dataform |
This is the dataform name that has the field to which you will match the Workspace Source Column. The Workspace Source Field of this dataform is matched against the Workspace Identifier column in the imported file to select the appropriate workspace in which to put the data. |
|
Fields |
This is how you add dataform fields to your configuration. See Configuring the Import Map Detail. |
|
Active |
When Active is selected (enabled), the import is active. Inactive imports are ignored. |
- Click Save.
- Continue to the next topic Configuring the Import Map Detail to add fields.